
Stay up to date on Tachyon.
MLflow's Missing Validators: An Authorization Bypass Across API Surfaces
Authorization bugs are some of the most dangerous vulnerabilities in software. If an attacker finds a gap, they can access data they shouldn't, take destructive actions, or cross tenancy boundaries.
They're also among the hardest to find.
Unlike injection bugs, there's no pattern to grep for. Authorization bugs are bugs of malformed logic—everything can look reasonable and still be wrong, because the failure mode is that a check didn't run on some path, or a check that did run is insufficient.
And unlike authentication, authorization has far less standardization. Authentication has well-worn protocols and mature libraries, along full SaaS solution like Clerk or WorkOS. Authorization, on the other hand, is very application-specific: roles, ownership, object hierarchies, and edge cases vary across products. Most teams roll their own.
This makes static automated detection unreliable. The usual source-to-sink taint model doesn't map cleanly to missing checks. Black-box scanners would need to discover the right users, roles, and state transitions, then generate specific request sequences that trigger a gap: a combinatorial problem that scales poorly.
This post walks through an authorization bypass that Tachyon found in MLflow, with details on how it surfaced a bug that traditional tooling would miss.
MLflow and the Authorization Invariant
MLflow is an open-source platform (built by Databricks) for managing the machine learning lifecycle. It’s used as a system of record for ML experimentation workflows. Teams track experiments, create runs, log parameters, and share trained models and eval outputs. They can also use it for inference, serving their models in production.
In a self-hosted deployment, MLflow typically sits at the center of an organization’s ML workflow. Multiple users and teams interact with the same tracking server. CI pipelines and evaluation jobs write results back, and production systems may pull artifacts from MLflow and load them dynamically.
In this system, the key security invariant is straightforward: every read or write of a protected resource must be authorized at the object level. The system must authenticate the user, understand their identity, and then verify whether that user is allowed to perform that action on that specific experiment, run, or artifact.
Inferring Auth Invariants
As an aside, one would expect this to be a simple invariant to infer. One would be wrong.
There are many widely used open-source projects with clear multi-tenant usage that ship without any builtin authorization, and consider it outside their domain. For example, Prometheus has historically taken the stance that authentication and authorization are out of scope, leaving operators to secure it externally. This comes up often in community discussions. Similar assumptions appear elsewhere: Jaeger’s UI does not provide native authentication and points users to reverse proxies instead, and Apache Spark is explicit in its documentation that its Web UIs do not include built-in auth filters, expecting operators to supply their own if needed.
This means that CVE-hunters, scanners, and anyone analyzing OSS projects, have to do quite a bit of meta work to determine whether a bypass is an actual in-scope vulnerability. This process of inferring scope is one of the hardest parts of building a reliable scanner.
But the simplicity of the invariant belied deep complexity in implementation. MLflow has over fifty API endpoints across three different protocols: gRPC, HTTP/REST (via Flask), and GraphQL. These were each added to the project at different times, by different engineers, in the service of different features. Each of those needs authorization enforcement; a single missing check is a security incident. That's where authorization bugs tend to hide: in the contextual and temporal gaps that emerge naturally as systems evolve.
Basic Auth, What Went Wrong, and Minimal Reproduction
MLflow’s experimental basic-auth mode (enabled via mlflow server --app-name=basic-auth or mlflow ui --app-name=basic-auth) is meant for multi-user deployments where resource-level access controls matter. In this configuration, requests are authenticated via HTTP Basic Auth, and MLflow enforces a permissions model over experiments and related resources.
How the authorization layer is structured
The key implementation detail is that basic-auth’s authorization is driven by an internal “validator” mechanism. A Flask before_request hook runs early in request handling:
- Authenticate the incoming request (establish the user identity).
- Attempt to look up an authorization validator for the request being made.
- If a validator is found, perform per-object authorization checks (e.g., “can this user read artifacts for this run?”).
Those validators are populated primarily from protobuf-registered REST endpoints—i.e., the canonical /api/2.0/mlflow/... routes.
Here's the core of the before_request hook in mlflow/server/auth/__init__.py:
@catch_mlflow_exception
def _before_request():
if _is_unprotected_route(request.path):
return
_user = _get_request_param("username")
_pwd = _get_request_param("password")
if _user and _pwd:
auth_client.authenticate_user(username=_user, password=_pwd)
return
# ... more auth methods ...
username = _get_username()
_validate_can_manage_experiment_permission(username)The function authenticates the request, then attempts to authorize. But the authorization step depends on finding a matching validator in an internal registry.
What went wrong: authorization attached to a registry, not to resource access
This design works only if every sensitive operation flows through routes covered by validators. The bypass occurs because MLflow also exposes alternate routes that reach the same protected resources but are not represented in the validator map.
Concretely:
- Authentication runs broadly.
- Authorization runs only when the request matches a validator entry.
- If no validator exists for the route, the request is authenticated but proceeds without per-object authorization checks—an allow-by-default fallthrough.
This failure mode is subtle because MLflow does have a permissions model, and it is enforced correctly on many endpoints. The bug isn't "no authorization exists"; it's that some endpoints were effectively off the books from the perspective of the authorization layer, so the policy simply never ran.
The critical fall-through logic looks like this:
def _get_permission_from_experiment_id() -> Permission:
experiment_id = _get_request_param("experiment_id")
username = _get_username()
return store.get_permission(experiment_id, username).permission
def _validate(validator: Callable[[], bool]):
if not validator():
raise MlflowException(
"Permission denied", error_code=PERMISSION_DENIED
)
# The validator map - only protobuf-registered endpoints are here
BEFORE_REQUEST_VALIDATORS = {
(http_path, method): _validate(permission_check)
for (http_path, method), permission_check in _get_permission_map().items()
}
def _before_request():
# ... authentication happens ...
# Authorization: look up validator for this route
validator = BEFORE_REQUEST_VALIDATORS.get((request.path, request.method))
if validator:
validator() # runs authorization check
# If no validator found: request proceeds without authorizationThe key line is the implicit else: if no validator is found in the map, the request is authenticated but not authorized, and it proceeds.
Two major uncovered surfaces are:
- Custom Flask routes / helper endpoints (e.g., artifact retrieval helpers) that aren’t protobuf-registered REST endpoints
- GraphQL (
/graphql), which reaches experiments/runs via resolvers but isn’t integrated into the same validator mechanism
Note that the before_request hook is applied in every case. The validator map is internal, used within the function to decide whether to trigger the authorization check.
Minimal reproduction: the “403 vs side door” contrast
In the setup below, an admin creates a run, uploads an artifact, and explicitly denies a non-admin user (NO_PERMISSIONS) on the experiment. The canonical REST artifacts API correctly blocks access:
curl -s -o /dev/null -w'%{http_code}\n' -H"Authorization: Basic $NON_ADMIN_TOKEN" \
"$API_URL/api/2.0/mlflow/artifacts/list?run_id=$RUN" # 403But the same artifact can be fetched via an alternate route that is not covered by the validator map:
curl -s -H"Authorization: Basic $NON_ADMIN_TOKEN" \
"$API_URL/get-artifact?run_id=$RUN&path=secret.txt" # returns full contentsOn affected versions, writes are also possible through an unvalidated upload route, enabling unauthorized artifact injection or overwrites:
curl -s -o /dev/null -w'%{http_code}\n' -H"Authorization: Basic $NON_ADMIN_TOKEN" \
--data-binary @<(printf "MALICIOUS CONTENT") \
"$API_URL/ajax-api/2.0/mlflow/upload-artifact?run_uuid=$RUN&path=malicious.txt"
# 200 - uploads successfullyThe GraphQL surface shows the same class of gap: a non-admin user can query run metadata via /graphql even when explicitly denied access.
How Tachyon found it
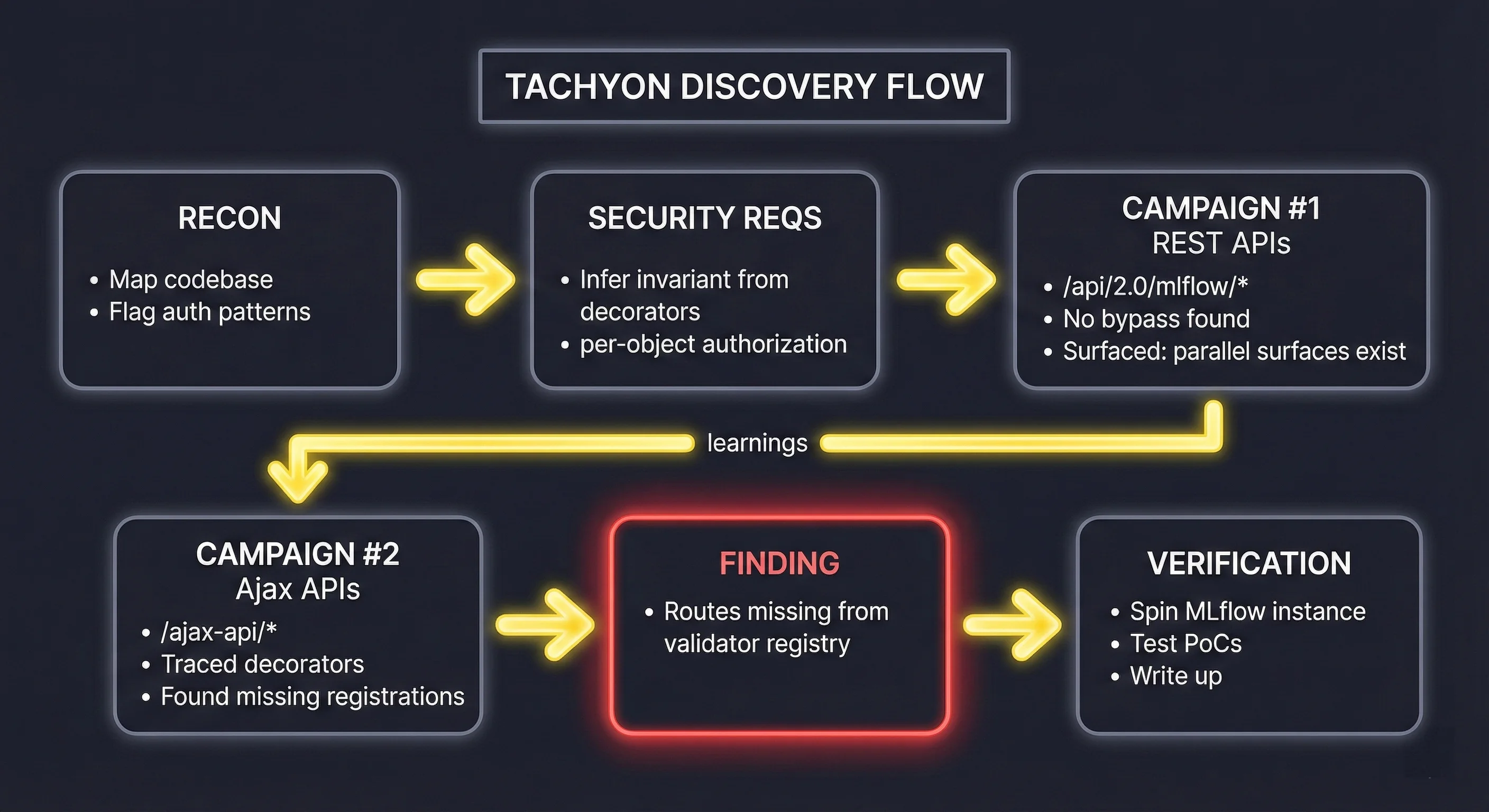
Tachyon's analysis proceeds in phases. The first is reconnaissance: mapping the codebase structure, identifying key components, and noting security-relevant patterns. During recon on MLflow, Tachyon flagged the basic-auth module and the before_request hook as central to authorization.
The second phase is security requirements derivation. Based on the widespread use of the @auth_required decorator and the BEFORE_REQUEST_VALIDATORS registry, Tachyon inferred that per-object authorization was an intended invariant: every endpoint accessing experiments, runs, or artifacts should be covered by the validator mechanism.
With this invariant established, Tachyon created a campaign to analyze authorization enforcement across the codebase. This took several rounds. The first set of agents analyzed the canonical REST APIs (/api/2.0/mlflow/). They didn't find bypasses there as the validators were correctly registered, but they surfaced learnings about the existence of multiple auth modes (no-auth, basic-auth) and parallel API surfaces (/ajax-api/, /graphql).
These findings triggered follow-on campaigns. One agent, assigned to analyze the /ajax-api/* routes under basic-auth mode, decided to trace back from the endpoint handlers to the decorator registration. It found that several artifact-related routes were missing from BEFORE_REQUEST_VALIDATORS—meaning the before_request hook would never invoke a permission check for those paths.
The next planning iteration picked up this signal, investigated it more deeply, and then proceeded to the final verificatin stage. It spun an MLflow instance, tested against it, and then wrote up proof-of-concepts demonstrating the bypass.
The Kill Chain
The immediate impact is straightforward: authenticated non-admin users can read restricted runs, experiments, and artifacts through unprotected routes and GraphQL. On affected versions, they can also upload or overwrite artifacts on restricted runs.
But this leads to a much broader set of possible attacks. Here’s one:
- Foothold: Attacker is a legitimate, authenticated non-admin user in a shared MLflow deployment (or has stolen such creds).
- Bypass: They hit an unvalidated route (/get-artifact, /ajax-api/.../upload-artifact, /graphql) that skips per-object authorization, letting them read restricted experiments/runs/artifacts—and on affected versions, write/overwrite artifacts.
- Poisoning: With write access, they upload or replace artifacts on runs they don’t control (e.g., model or python_function artifacts).
- Privilege escalation via trust: A higher-privileged process (admin review, CI/eval job, or serving system) later pulls and loads those artifacts. If the artifact format is executable, this can become code execution in a privileged context.
- Lateral movement: The attacker now has a path to spread impact to any downstream system that consumes MLflow artifacts, turning a permissions gap into a supply-chain-style incident.
Lessons
Two general lessons come out of this incident.
First, authorization should fail closed. If an authorization layer is driven by a registry or map, missing registry entries must not translate into "no authorization performed." Otherwise the security posture depends on the completeness of endpoint registration, which is rarely stable over time.
Second, multi-surface services should unify authorization at the resource layer. If experiments, runs, and artifacts are protected objects, then the operations that read and write them should enforce permissions regardless of which protocol or route is used to reach them. This reduces the chance that adding a new interface (a helper route, a new UI endpoint, a GraphQL resolver) creates a bypass simply because it was not wired into the original enforcement mechanism.
Disclosure
This issue was responsibly disclosed on Huntr. It has since been published.